ELF from scratch

I’m learning about ELF, the binary file format for Linux, BSD and others. It is full of interesting information and serves as a good introduction to assembly programming.
High level overview
My first search leads me to the Wikipedia page about ELF. It says something about “tables” and “sections” but everything is still blurry and I want to get a deeper understanding. To learn more, I open up the man elf in my terminal.
Things start to clear up a bit. There are 4 parts in an ELF file:
- the ELF header;
- the program header table;
- the section header table;
- and data referenced by said tables.
Header structure
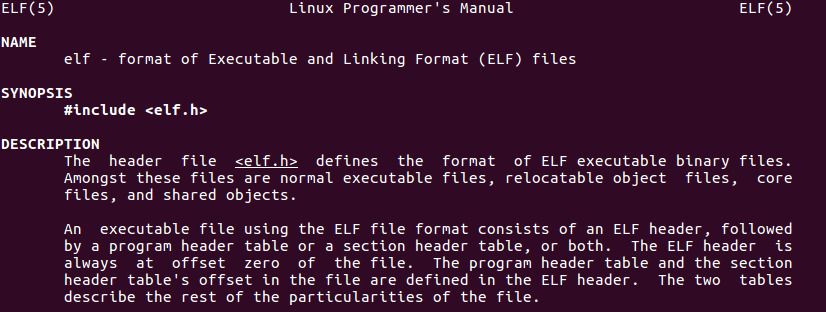
Further down in the manpage, there are more details about the structure of the ELF header. Lots of stuff to examine. It would be interesting to write a C program to try and print out the values contained in this header, for instance for the /bin/ls binary.
I start off by mapping /bin/ls to memory, so I can later read the header bits:
#include <string.h>
#include <sys/mman.h>
#include <elf.h>
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include <fcntl.h>
int main() {
const char *ls = NULL;
int fd = -1;
struct stat stat = {0};
// open the /bin/ls file with read-only permission
fd = open("/bin/ls", O_RDONLY);
if (fd < 0) {
perror("open");
goto cleanup;
}
// find the size of /bin/ls
if (fstat(fd, &stat) != 0) {
perror("stat");
goto cleanup;
}
printf("Everything is OK!\n");
// put the contents of /bin/ls in memory
ls = mmap(NULL, stat.st_size, PROT_READ, MAP_PRIVATE, fd, 0);
if (ls == MAP_FAILED) {
perror("mmap");
goto cleanup;
}
// close file descriptors and free memory before the program exits
cleanup:
if (fd != -1) {
close(fd);
}
if (ls != MAP_FAILED) {
munmap((void *)ls, stat.st_size);
}
return 0;
}
I use mmap because it allows me to access the contents as if it were a large vector of bytes, instead of using multiples successive calls to read. And because this program is only for testing purposes, I forgo out of bounds checking for now.
Then I compile with gcc and run the program against /bin/ls:
gcc -Wall -Wextra -Werror elf.c -o elf && ./elf /bin/ls
The debug message “Everything is OK!” is output to my terminal, good.
Now, I’d like to replace this debug message with code that reads specific parts /bin/ls based on what the ELF header tells me. I want to go over each and every property of the Elf64_Ehdr structure and learn about their meaning.
However, I’m not interested in the properties e_ident[EI_VERSION], e_machine, e_version and e_flags because the manpage is quite clear about what they do.
e_ident[EI_MAG0] and friends
It looks like ELF files contain a series of bytes that allow to quickly recognize it as an ELF file and not a jpg or an mp4. This doesn’t guarantee that a file containing these bytes is necessarily a valid ELF file, but at least, we can expect that it probably is.
I test this against /bin/ls:
if (
(unsigned char)ls[EI_MAG0] == 0x7f &&
(unsigned char)ls[EI_MAG1] == 'E' &&
(unsigned char)ls[EI_MAG2] == 'L' &&
(unsigned char)ls[EI_MAG3] == 'F'
) {
printf("Yes, this is an ELF file!\n");
}
I see “Yes, this is an ELF file!”, so /bin/ls has the correct header for an ELF file. Good first step.
e_ident[EI_CLASS]
From the docs, the memory slot EI_CLASS should contain either ELFCLASS32 or ELFCLASS64. These values respectively mean that the binary ELF file is meant to work on a 32 bits system or a 64 bits system. My laptop has a 64 bit CPU and I installed a 64 bits version of Linux, so I expect ELFCLASS64:
if ((unsigned char)ls[EI_CLASS] == ELFCLASS64) {
printf("Yes, this file is made for 64 bits!\n");
}
And indeed, I get some output, so /bin/ls on my laptop is a 64 bits version.
I’m curious to see if that still works with a 32 bits program on my 64 bits Linux though. So I try and find a way to compile a little program for 32 bits and display its ELF header. Here’s what I’ve got:
# install the 32 bits libc
sudo apt install gcc-multilib
# create a test file in C that displays "Hello world!"
echo '#include <stdio.h>' >> elf-32.c
echo 'int main() { printf("Hello world!\n"); return 0; }' >> elf-32.c
# compile the file for 32 bits
gcc -m32 -Wall -Wextra -Werror elf-32.c
# read the EI_CLASS value
readelf -h a.out | grep -e '^\s*Class'
The call to readelf shows Class: ELF32 as expected.
On a side note, the manpage talks about an ELFCLASSNONE value possible for EI_CLASS. Although it’s unclear for me at first, I eventually find out it is used to indicate an invalid EI_CLASS by programs that analyse ELF binary files, for instance readelf.
e_ident[EI_DATA]
Now, I go on to the EI_DATA field. This memory slot says whether the ELF file is meant for a little-endian or big-endian computers. I always thought that this was a choice at the operating system level. Actually, it’s a choice at the CPU level. Just as an example, my 64 bits Intel CPU uses little-endian. And it turns out that Linux supports big-endian architectures as well, for instance AVR32 microcontrollers.
For little-endian, the manpage says I should expect EI_DATA to be ELFDATA2LSB:
if ((unsigned char)ls[EI_DATA] == ELFDATA2LSB) {
printf("Yes, compiled for little-endian!\n");
}
And sure enough, it does.
e_ident[EI_OSABI]
Next up is the EI_OSABI field which should tell me about the operating system and ABI. At this point, I first have lookup what ABI means. It means how the different bits of already compiled code access each other. Since I run Linux, I expect ELFOSABI_LINUX here:
if ((unsigned char)ls[EI_OSABI] == ELFOSABI_LINUX) {
printf("Yes, this is a Linux binary!\n");
}
But for some reason, I don’t get any output here. So my /bin/ls is not ELFOSABI_LINUX. I go back to the manpage to see if I’ve overlooked anything. If the ABI of /bin/ls isn’t Linux, maybe it is ELFOSABI_NONE or ELFOSABI_SYSV. I don’t know what it is, but since it looks like the most generic one, it’s worth a try.
Here’s the test:
if ((unsigned char)ls[EI_OSABI] == ELFOSABI_SYSV) {
printf("Yes, this is a SYSV binary!\n");
}
And, this time I get the confirmation message.
I think the ELFOSABI_SYSV is probably the ABI that was used on the System V operating system before Linux chose to use the same. However, I’m not 100% sure of that. It seems that the memory slot EI_OSABI is the source of great confusion. On the one hand, some people say that EI_OSABI identifies the kernel:
elf_osabi identifies the kernel, not userland
On the other hand, it seems that most ELF files on Linux use ELFOSABI_SYSV instead of ELFOSABI_LINUX:
All the standard shared libraries on my Linux system (Fedora 9) specify ELFOSABI_NONE (0) as their OSABI.
Except on recent versions of Fedora :
Possibly the vendor is cross compiling on FreeBSD or using a very recent Fedora system where anything using STT_GNU_IFUNC will be marked as ELFOSABI_LINUX.
And finally, the man elf says that some flags can be platform=specific.
Some fields in other ELF structures have flags and values that have platform-specific meanings; the interpretation of those fields is determined by the value of this byte.
In the end, what I get from this is that Linux mostly uses the SYSV ABI, but maybe someday the LINUX ABI will contain Linux specific things that the Linux kernel will then be able to interpret in a somewhat different way than it would with the SYSV ABI.
e_type
Next up in the ELF header structure is the e_type field. This should be the type of ELF file currently being read. It could be one of: ET_REL, ET_CORE, ET_NONE, ET_EXEC, ET_DYN.
ET_EXEC and ET_DYN seem quite clear to me, an executable and a shared library. But I have no idea what ET_REL, ET_CORE and ET_NONE are.
ET_REL
I did some many Google searches about this that I can’t remember them all.
What I ended up understanding though, is that ET_REL stand for “relocatable”. That means a piece of code that isn’t in its final place and will be added to other code to form an executable.
From my somewhat partial understanding, that could mean object files or static libraries.
ET_CORE
According to gabriel.urdhr.fr, ET_CORE is used for core dumps. I want to see this with my own eyes though. So I try to create a core dump by triggering a segfault:
echo 'int main() {return (*(int *)0x0);}' > test.c
gcc -Wall -Wextra -Werror test.c
./a.out
I get a segmentation fault as expected, and a core dump:
Segmentation fault (core dumped)
However, I can’t find the coredump file anywhere. As it turns out, Ubuntu doesn’t generate core dump files. Instead, Apport sends crash reports to a webservice managed by Canonical to help them fix bugs. I learn through a StackOverflow thread on core dumps that I can see where core dumps go by running cat /proc/sys/kernel/core_pattern as root.
Then I learn about the gcore utility which allows generating a core dump for any running program. Running readelf -a on that core dump shows “Type: CORE (Core file)” as expected.
I also try looking for core dumps on an Arch Linux laptop. On Arch Linux, coredumps are stored in /var/lib/systemd/coredump/. And again, running readelf -a shows “Type: CORE (Core file)” for those files.
ET_NONE
Same as ELFCLASSNONE, it seems like ET_NONE is rarely used. I wonder if this value is used by ELF file parsers to indicate invalid ELF file contents when needed. Given that I’ve had the same question with ELFCLASSNONE before, I ask on Stackoverflow. Just minutes later, someone answered:
Anywhere validity of the ELF file is verified. Here is an example from the Linux kernel tools.
Tests
Now, I want to run some code just to make sure that I understand the different values of e_type:
# create a minimal program
echo 'int main() { return 0; }' > test.c
# compile to executable form, should be ET_EXEC
gcc -Wall -Wextra -Werror test.c
readelf -h a.out | grep -e '^\s*Type'
# create a minimal library
echo 'int test() { return 0; }' > test.c
# compile to object form, should be ET_REL
gcc -c -fPIC -Wall -Wextra -Werror test.c
readelf -h test.o | grep -e '^\s*Type'
# compile to a static library, should be ET_REL too
ar -r libtest.a test.o
readelf -h libtest.a | grep -e '^\s*Type'
# compile to a shared library, should be ET_DYN
gcc -shared test.o -o libtest.so
readelf -h libtest.so | grep -e '^\s*Type'
# create a coredump, should be ET_CORE
sudo gcore 1
readelf -h core.1 | grep -e '^\s*Type'
The output is as expected:
Type: EXEC (Executable file)
Type: REL (Relocatable file)
Type: REL (Relocatable file)
Type: DYN (Shared object file)
Type: CORE (Core file)
What’s a bit surprising is that running the same tests on Arch Linux does not yield the same results. Instead of EXEC for the first line, I get DYN. This may be related to PIE per this StackOverflow thread about “EXEC” being reported as “DYN”. Maybe gcc has different default options on Arch Linux than it does on Ubuntu.
e_entry
According to the man page, e_entry points to the first instruction that the CPU will execute when a program starts. Compiling a very simple program with some assembly should allow me to verify this:
void _start() {
// _exit(0)
asm(
"mov $0, %rdi;"
"mov $60, %rax;"
"syscall;"
);
}
Then I compile and link, with ld instead of gcc to avoid including the libc:
gcc -c -Wall -Wextra -Werror test.c && ld test.o
Finally, in the test program, I print out the e_entry:
printf("Entry: %lu\n", ((Elf64_Ehdr *)ls)->e_entry);
Here, the output value is 4194480 so I expect to find the assembly instructions from above precisely at that address in the a.out binary. I dump the binary using objdump -d a.out:
a.out: file format elf64-x86-64
Disassembly of section .text:
00000000004000b0 <_start>:
4000b0: 55 push %rbp
4000b1: 48 89 e5 mov %rsp,%rbp
4000b4: 48 c7 c7 00 00 00 00 mov $0x0,%rdi
4000bb: 48 c7 c0 3c 00 00 00 mov $0x3c,%rax
4000c2: 0f 05 syscall
4000c4: 90 nop
4000c5: 5d pop %rbp
4000c6: c3 retq
The assembly instructions are at addresses 0x4000b4, 0x4000bb (0x3c is 60 in base 10) and 0x4000c2. The _start function is located at address 0x4000b0, which is 4194480 in base 10, as expected.
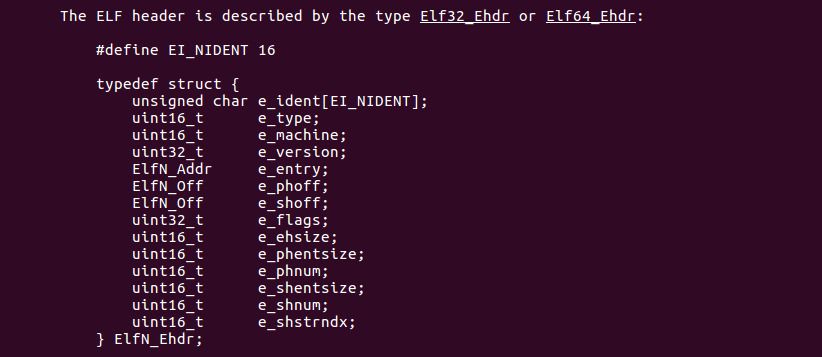
e_phoff, program headers
Next up in the ELF header is e_phoff, which refers to program headers. Further down in the ELF manual is more information about program headers:
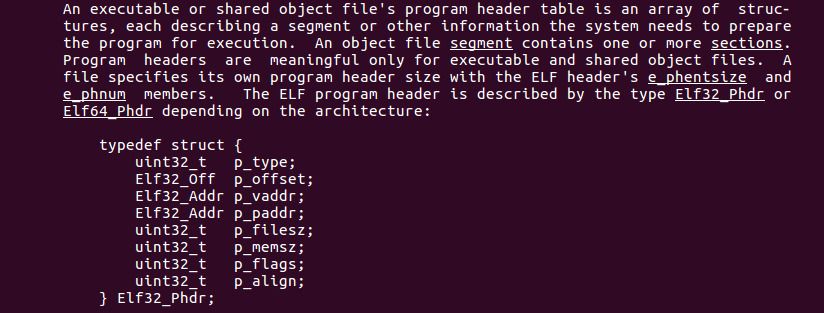
These headers describe bits of memory called “segments” which contain instructions that will run at process startup. This means that shared libraries and object files most likely don’t contain program headers, since those types of files are not executable. Running readelf -l test.o confirms that.
At this point, I’m unsure what precisely is in a “segment”. What’s the difference between a “section” and a “segment”? They feel like they are the same. Before studying “sections”, whose understanding will hopefully help me understand “segments”, I want to run a few tests to see if I can read the contents of a program header.
#define TEST_HEADER_TYPE(type, value, name)\
if ((type) == (value)) {\
printf("%s\n", (name));\
}
Elf64_Ehdr *eh = (Elf64_Ehdr *)ls;
for (int i = 0; i < eh->e_phnum; i++) {
Elf64_Phdr *ph = (Elf64_Phdr *)((char *)ls + (eh->e_phoff + eh->e_phentsize * i));
uint32_t type = ph->p_type;
// all the p_type can be found in /usr/include/elf.h
TEST_HEADER_TYPE(type, PT_NULL, "PT_NULL");
TEST_HEADER_TYPE(type, PT_LOAD, "PT_LOAD");
TEST_HEADER_TYPE(type, PT_DYNAMIC, "PT_DYNAMIC");
TEST_HEADER_TYPE(type, PT_INTERP, "PT_INTERP");
TEST_HEADER_TYPE(type, PT_NOTE, "PT_NOTE");
TEST_HEADER_TYPE(type, PT_SHLIB, "PT_SHLIB");
TEST_HEADER_TYPE(type, PT_PHDR, "PT_PHDR");
TEST_HEADER_TYPE(type, PT_TLS, "PT_TLS");
TEST_HEADER_TYPE(type, PT_NUM, "PT_NUM");
TEST_HEADER_TYPE(type, PT_LOOS, "PT_LOOS");
TEST_HEADER_TYPE(type, PT_GNU_EH_FRAME, "PT_GNU_EH_FRAME");
TEST_HEADER_TYPE(type, PT_GNU_STACK, "PT_GNU_STACK");
TEST_HEADER_TYPE(type, PT_GNU_RELRO, "PT_GNU_RELRO");
TEST_HEADER_TYPE(type, PT_LOSUNW, "PT_LOSUNW");
TEST_HEADER_TYPE(type, PT_SUNWBSS, "PT_SUNWBSS");
TEST_HEADER_TYPE(type, PT_SUNWSTACK, "PT_SUNWSTACK");
TEST_HEADER_TYPE(type, PT_HISUNW, "PT_HISUNW");
TEST_HEADER_TYPE(type, PT_HIOS, "PT_HIOS");
TEST_HEADER_TYPE(type, PT_LOPROC, "PT_LOPROC");
TEST_HEADER_TYPE(type, PT_HIPROC, "PT_HIPROC");
}
Here’s what I get:
PT_PHDR
PT_INTERP
PT_LOAD
PT_LOAD
PT_DYNAMIC
PT_NOTE
PT_GNU_EH_FRAME
PT_GNU_STACK
PT_GNU_RELRO
The reassuring thing is that I find the same types of program headers when I run readelf -l /bin/ls.
e_shoff, section headers
On to section headers. The manual doesn’t say much about them:
A file’s section header table lets one locate all the file’s sections.
Differences with segments
It seems like sections (pointed by section headers) and segments (pointed by program headers) are closely related. There are some differences between program and section headers though. The section header has something the program header doesn’t have: e_shstrndx. It looks like this is the index of the section header for section .shstrtab, which contains the names of all of the sections. Inception!
What this tells me is that I can probably get the buffer that contains all section names like this:
Elf64_Ehdr *elf_header = (Elf64_Ehdr *)ls;
Elf64_Shdr *shstrtab_header = (Elf64_Shdr *)((char *)ls + (eh->e_shoff + eh->e_phentsize * eh->e_shstrndx));
# this is a buffer that contains the names of all sections
const char *shstrtab = (const char *)ls + shstrtab_header->sh_offset;
What’s the format of the shstrtab buffer though? The ELF specification defines the format of a “String table”. What stands out for me is that each section has a name. That name is stored in the section string table as a C string at a specified index.
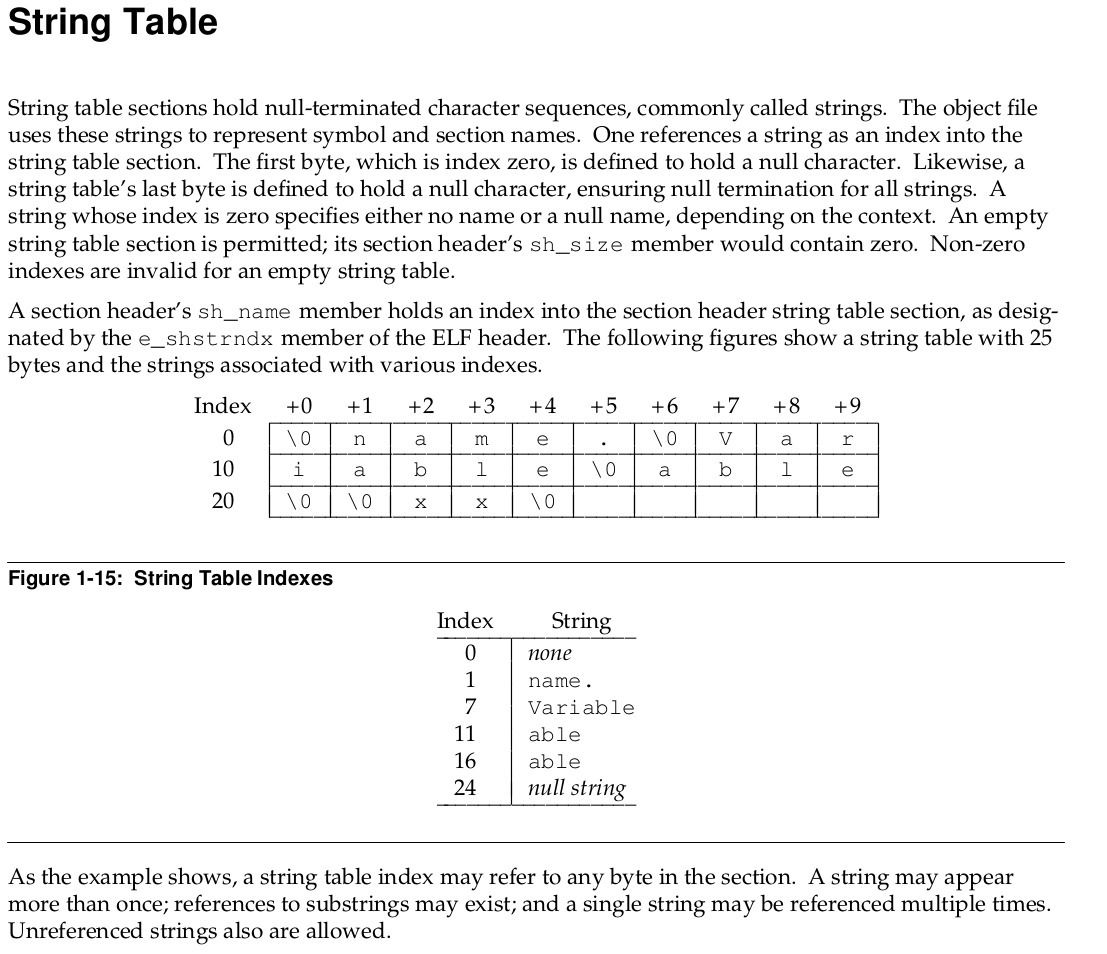
Commonality with segments
Sure, there are differences between sections and segments. But some things are the same. For instance, program headers have a type PT_DYNAMIC and section headers have SHT_DYNAMIC. This “Introduction to ELF” by Red Had says they are the same:
SHT DYNAMIC dynamic tags used by rtld, same as PT DYNAMIC
But I have a problem. I can’t find anything that explains what “dynamic tags used by rtld” means. Page 42 of the ELF specification shows that segments of type PT_DYNAMIC and sections of type SHT_DYNAMIC contain ElfN_Dyn structs. Back in elf’s man page, we can see that these structs contain a d_tag field. Probably the “dynamic tag” that Red Hat was talking about.

This d_tag is interesting. The manual tells me that it can have the type PT_NEEDED, in which case it contains an index into the string table .strtab, so that I can effectively get the name of a shared library that the ELF file depends on. I want to try this with the following steps:
- find the
PT_DYNAMICsegment; - inside the
PT_DYNAMICsegment, find thed_tagwith typeDT_STRTABso I know where the.strtabis; - inside the
PT_DYNAMICsegment, for eachd_tagof typeDT_NEEDED, print out the C string that is inside.strtabat indexd_un.d_val, which should be the name of a shared library.
Elf64_Ehdr *eh = (Elf64_Ehdr *)ls;
for (int i = 0; i < eh->e_phnum; i++) {
Elf64_Phdr *ph = (Elf64_Phdr *)((char *)ls + (eh->e_phoff + eh->e_phentsize * i));
if (ph->p_type == PT_DYNAMIC) {
const Elf64_Dyn *dtag_table = (const Elf64_Dyn *)(ls + ph->p_offset);
// look for the string table that contains the names of the
// shared libraries need by this ELF file
const char *strtab = NULL;
for (int j = 0; 1; j++) {
// the end of table of Elf64_Dyn is marked with DT_NULL
if (dtag_table[j].d_tag == DT_NULL) {
break;
}
if (dtag_table[j].d_tag == DT_STRTAB) {
strtab = (const char *)dtag_table[j].d_un.d_ptr;
}
}
// if there is no string table, we are stuck
if (strtab == NULL) {
break;
}
// now, I'll look for shared library names inside the string table
for (int j = 0; 1; j++) {
// the end of table of Elf64_Dyn is marked with DT_NULL
if (dtag_table[j].d_tag == DT_NULL) {
break;
}
if (dtag_table[j].d_tag == DT_NEEDED) {
printf("shared lib: %s\n", &strtab[dtag_table[j].d_un.d_val]);
}
}
// only look into PT_DYNAMIC
break;
}
}
At first sight, everything works as expected. When I run ./a.out on the a.out ELF file instead of /bin/ls, so when I try to find what shared libraries a.out needs, I get:
shared lib: libc.so.6
However, when I try to read shared libraries of system binaries like /bin/ls, I get a segmentation fault. gdb tells me that something is wrong with my printf call. Specifically, gdb tells me that the memory I am trying to access isn’t available:
strtab = 0x401030 <error: Cannot access memory at address 0x401030>That’s odd, because readelf -a /bin/ls | grep 401030 shows that the .dynstr section is actually at address 0x401030. I’m a little lost here. Again, I ask call Stackoverflow to the rescue. And the same person that previously answered on Stackoverflow answers one more time:
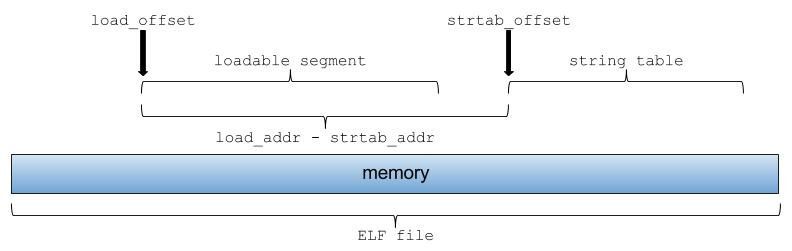
If the binary isn’t running, you need to relocate this value by$where_mmaped - $load_addr. The$where_mmapedis yourlsvariable. The$load_addris the address where the binary was statically linked to load (usually it’s thep_vaddrof the firstPT_LOADsegment; for x86_64 binary the typical value is0x400000).
Now that I think about it, I think there was something about that in the manual. But I had overlooked it:
When interpreting these addresses, the actual address should be computed based on the original file value and memory base address.
With this help, here’s how memory is laid out:
Here’s the fixed version of the previous test program:
Elf64_Ehdr *eh = (Elf64_Ehdr *)ls;
// look for the PT_LOAD segment
const char *load_addr = NULL;
uint32_t load_offset = 0;
for (int i = 0; i < eh->e_phnum; i++) {
Elf64_Phdr *ph = (Elf64_Phdr *)((char *)ls + (eh->e_phoff + eh->e_phentsize * i));
// I've found the PT_LOAD segment
if (ph->p_type == PT_LOAD) {
load_addr = (const char *)ph->p_vaddr;
load_offset = ph->p_offset;
break;
}
}
// if there is no PT_LOAD segment, we are stuck
if (load_addr == NULL) {
goto cleanup;
}
for (int i = 0; i < eh->e_phnum; i++) {
Elf64_Phdr *ph = (Elf64_Phdr *)((char *)ls + (eh->e_phoff + eh->e_phentsize * i));
if (ph->p_type == PT_DYNAMIC) {
const Elf64_Dyn *dtag_table = (const Elf64_Dyn *)(ls + ph->p_offset);
// look for the string table that contains the names of the
// shared libraries need by this ELF file
const char *strtab = NULL;
for (int j = 0; 1; j++) {
// the end of table of Elf64_Dyn is marked with DT_NULL
if (dtag_table[j].d_tag == DT_NULL) {
break;
}
if (dtag_table[j].d_tag == DT_STRTAB) {
// mark the position of the string table
const char *strtab_addr = (const char *)dtag_table[j].d_un.d_ptr;
uint32_t strtab_offset = load_offset + (strtab_addr - load_addr);
strtab = ls + strtab_offset;
}
}
// if there is no string table, we are stuck
if (strtab == NULL) {
break;
}
// now, I'll look for shared library names inside the string table
for (int j = 0; 1; j++) {
// the end of table of Elf64_Dyn is marked with DT_NULL
if (dtag_table[j].d_tag == DT_NULL) {
break;
}
if (dtag_table[j].d_tag == DT_NEEDED) {
printf("shared lib: %s\n", &strtab[dtag_table[j].d_un.d_val]);
}
}
// only look into PT_DYNAMIC
break;
}
}
Now, everything works as expected, with both a.out and /bin/ls.
I conclude that program headers are useful to an executable file whereas section headers are useful to shared/object files during the link phase. Both types of headers point to memory addresses that will end up in the executable file in the end, but don’t describe the memory contents in the same way or with the same granularity.
GOT and PLT
In the man elf, there are multiple references to GOT and PLT. The best explanation I could find is “PLT and GOT, the key to code sharing and dynamic libraries” at TechNovelty.org:
- the GOT stores addresses of variables that are unknown at compile time but known at link time;
- the PLT stores addresses of functions from shared libraries that unknown both at compile time and at link time (if compiled with
-fPICwhich is often the case), and are to be resolved dynamically at runtime.
Additional searches about GOT and PLT on DDG, I find an article that shows how to exploit the GOT to execute a shellcode. Another interesting find is this paper published by Leviathan Security about a modified ELF file format specifically made for forensic analysis.