x86-64 assembly from scratch

I’m taking the deep dive into x86-64 assembly. Or at least I’m dipping my toes.
Introduction to assembly
Because my computer has a 64 bits CPU, the easiest way to get started is probably to use the assembly that works on my computer. That would be x86-64, although I sometimes see the terms x64 or amd64 being used too. I am new to assembly. I have seen some assembly code and have studied 68K assembly at university. But that was only on paper. I’ve never actually compiled and run assembly code. I want to remedy that.
Looking for x64 linux assembly on DuckDuckGo, I find this Stackoverflow thread that has some good tips on learning assembly, both on what to do and what not to do.
What not to do:
The Intel documentation is a bad place to start learning assembler.
What to do:
Take a look here (http://asm.sourceforge.net) it’s the best place for Linux Assembly development, you will find resources, docs and links.
This website, asm.sourceforge.net, seems a bit complicated though. So I try to find some easier guides, ideally aimed at total beginners. This series of tutorials by 0xAX turns is a goldmine. It documents the learning steps for x86-64 assembly. It looks like a great place to start learning assembly. It lists basic information like what registers are available and their different forms (64 bits, 32 bits, etc) with the corresponding names (ie rax, eax, ax, al for the first register).
It gives the command I need to install the NASM compiler on Ubuntu:
sudo apt-get install nasm
And the commands I need to compile and link assembly file to actually get a working program:
nasm -f elf64 -o hello.o hello.asm
ld -o hello hello.o
As is assembly for the most part, nasm is new to me. I’d like to know more. DuckDuckGo leads me to the nasm documentation. I highly recommend glancing through it: it is easy to read and contains lots of tips for assembly development with nasm.

One thing this documentation teaches me is that there are 3 different ways to define strings with nasm:
db 'Hello world', 10 ; with single quotes
db "Hello world", 10 ; with double quotes
db `Hello world\n` ; with backticks, \n, \r, \t, etc are available
This documentation also gives a trick to get the length of a string. It looks like a pointer subtraction, $ being the pointer to the current instruction, ie the end of the string, and message being the pointer to the beginning of the string:
message db 'hello, world'
msglen equ $-message
Calling conventions
School 42 has a course on assembly. It says the following:
Be aware of the “calling conventions”
Not knowing what “calling conventions” are, I go back to DuckDuckGo which leads me to wiki.osdev.org:
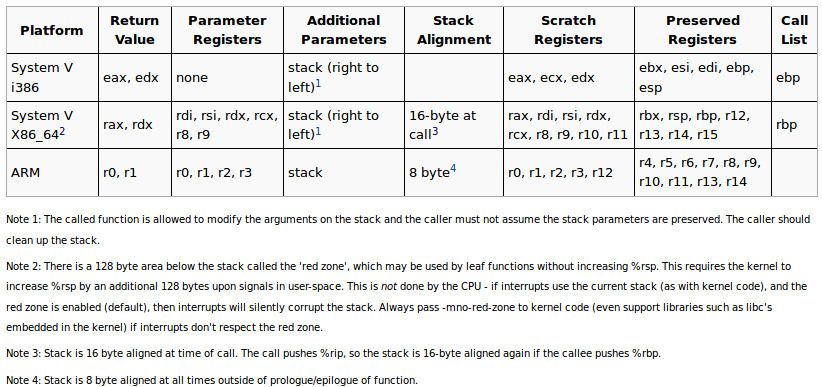
What I understand from this graphic is that the “calling convention” defines what registers have which role when I call a function. For instance, if I call a function with 2 parameters, I’ll put the first parameter value in rdi and the second parameter value in rsi. The function must put the return value in rax.
This means that, where I would do this in C:
int return_value_of_my_function = my_function(42);
printf("%d\n", return_value_of_my_function);
In assembly, I would do this (pseudo-code):
rdi <= 42
call my_function
rdi <= "%d\n"
rsi <= rax
call printf
Stack alignment
In school 42’s e-learning platform, the video dedicated to assembly talks about “stack alignment”, without giving much information about what it is. Searching for “stack alignment” on DuckDuckGo, I find this StackOverflow answer on “stack alignment” which is a great introduction to the topic. Worth a read!
First program, without libc
Now that I have the basics down, I want to create a real program. One that I can run in my terminal. I start with “Hello world”.
To write a functional “Hello world”, I need to call the write system call. How can I do a syscall with nasm though? A Stackoverflow question about syscalls suggests reading the psABI-x86-64. And here is what that document says:
A system-call is done via the syscall instruction. The kernel destroys registers %rcx and %r11.The number of the syscall has to be passed in register %rax.
Moreover, I know from looking at the ELF file format that read-only data is saved in the .rodata section and that executable code is saved in the .text section. So here is the first version of assembly “Hello world”:
section .rodata
msg: db 'hello, world', 10
msglen: equ $-msg
section .text
main:
; write(1, msg, msglen)
mov rdi, 1
mov rsi, msg
mov rdx, msglen
mov rax, 1
syscall
What’s happening here? I put 1 into rax and then use the syscall instruction. This calls write, which has syscall number 1, as can be seen in this syscall table. Then I compile and run:
nasm hello.s -f elf64 -o hello.o && ld hello.o -o hello
But, I get a warning:
ld: warning: cannot find entry symbol _start; defaulting to 0000000000400080
I guess there is a mistake here. It looks like unlike with C, the main function can’t be called main. Looking for “cannot find entry symbol _start asm” on DuckDuckGo, I find out that my code should look like this:
.text
global _start
_start:
; code goes here
The global keyword indicates that the symbol _start is accessible from outside the current module, hello.s in this case. And looking at elf’s man page, I can actually see that this global keyword is translated into a STB_GLOBAL flag:

Anyway, I replace main with _start and add global _start:
section .rodata
msg: db 'Hello world', 10
msglen: equ $-msg
section .text
global _start
_start:
; write(1, msg, msglen)
mov rdi, 1
mov rsi, msg
mov rdx, msglen
mov rax, 1
syscall
Then, I recompile and execute the program with ./hello:
Hello world
Segmentation fault (core dumped)
Woops! But I’m not the only one with this issue, as this Stackoverflow question on segmentation faults with NASM shows:
Because ret is NOT the proper way to exit a program in Linux, Windows, or Mac!!!! For Windows it is ExitProcess and Linux is is system call - int 80H using sys_exit, for x86 or using syscall using 60 for 64Bit or a call to exit from the C Library if you are linking to it.
So I try using the exit syscall:
section .rodata
msg: db 'Hello world', 10
msglen: equ $-msg
section .text
global _start
_start:
; write(1, msg, msglen)
mov rdi, 1
mov rsi, msg
mov rdx, msglen
mov rax, 1
syscall
; exit(0)
mov rdi, 0
mov rax, 60
syscall
This time, compiling and running works as expected.
First program, with libc
Now that I’ve got a working program without libc, I want to try adding libc into the mix. I’d also like to use printf instead of the write syscall. The first step to try compiling with libc, using gcc instead of ld:
nasm hello.s -f elf64 -o hello.o && gcc -Wall -Wextra -Werror -o hello hello.o
I get an error. This time, it looks like main is missing:
hello.o: In function `_start':
hello.s:(.text+0x0): multiple definition of `_start'
/usr/lib/gcc/x86_64-linux-gnu/5/../../../x86_64-linux-gnu/crt1.o:(.text+0x0): first defined here
/usr/lib/gcc/x86_64-linux-gnu/5/../../../x86_64-linux-gnu/crt1.o: In function `_start':
(.text+0x20): undefined reference to `main'
collect2: error: ld returned 1 exit status
So I go back to the code and replace _start with main. I also replace exit(0) with return 0 because libc automatically calls return at the end of the main function.
section .rodata
msg: db 'Hello world', 10
msglen: equ $-msg
section .text
global main
main:
; write(1, msg, msglen)
mov rdi, 1
mov rsi, msg
mov rdx, msglen
mov rax, 1
syscall
; return 0
mov rax, 0
ret
After compiling and running ./hello, I get “Hello world”. It works as expected.
Replacing write with printf
Now that I have the libc in place, my next goal is to replace write with printf. On 42’s e-learning platform, there was an example printf call that show I had to use extern printf. The extern keyword is described in the NASM documentation:
EXTERN (…) is used to declare a symbol which is not defined anywhere in the module being assembled, but is assumed to be defined in some other module and needs to be referred to by this one.
This is what I get once I’ve added these bits of code:
section .rodata
format: db 'Hello %s', 10
name: db 'Conrad'
section .text
global main
extern printf
main:
; printf(format, name)
mov rdi, format
mov rsi, name
call printf
; return 0
mov rax, 0
ret
To make things a bit more interesting, I set printf’s first argument to a format as opposed to a regular string.
After compiling and running the program, I get a Segmentation fault once again. Because printf has variable arguments, I think maybe I’m not using the calling convention correctly. As is often the case Stackoverflow has a question and an answer about the printf calling convention:
Yes, RAX (actually AL) should hold the number of XMM registers used.
I have no idea what XMM registers are though, so I don’t think I’ve used any. I try to add mov rax, 0 before calling printf and see what happens:
Hello Conrad
Conrad
Better! The segfault is gone. But for some reason, my first name is output twice. After fiddling around a bit, I realise that printf expects a C string that has \0 at the end. After adding \0, this is what my assembly code looks like:
section .rodata
format: db 'Hello %s', 10, 0
name: db 'Conrad', 0
section .text
global main
extern printf
main:
; printf(format, name)
mov rdi, format
mov rsi, name
; no XMM registers
mov rax, 0
call printf
; return 0
mov rax, 0
ret
I compile and run ./hello:
Hello Conrad
It works!
Rewriting bzero
Now, I’d like to clone a “simple” from the libc in assembly. This should be a good way to learn about other x86-64 instructions. I need to find out how to do loops and index incrementation. The prototype of bzero is void bzero(void *s, size_t n). This means that the rdi register is a pointer to s and the rsi register is the number of bytes to set to 0. The simplest way to clone bzero should be something like this:
while (--rsi >= 0) {
rdi[rsi] = 0;
}
For --rsi, there seems to be a well-suited DEC instruction, as can be seen in the x64 instruction set published by Intel.
For the >= 0 comparison, the Jcc instructions seem appropriate. They set the instruction pointer to a specific address depending on predefined conditions:
The condition codes used by the Jcc, CMOVcc, and SETcc instructions are based on the results of a CMP instruction.
For rdi[rsi] = 0, I think the MOV instruction should work. The nasm docs on indexing know how to tell MOV how to copy at the rsi index of rdi: mov word [addr], val.
Knowing this, the assembly version of bzero should more likely be something like this:
while (1) {
rsi--; // DEC
if (rsi < 0) return; // CMP, JL
rdi[rsi] = 0; // MOV, JMP
}
I end up with the following assembly version of bzero:
section .text
global my_bzero
my_bzero:
.loop:
; rsi--
dec rsi
; if (rsi < 0) return
cmp rsi, 0
jl .ret
; rdi[rsi] = 0
mov byte [rdi+rsi], 0
jmp .loop
.ret:
ret
I’ve replaced mov word [...], 0 with mov byte [...], 0 after realising that word means 16 bits instead of 8 bits. My goal is to copy one byte (8 bits) at a time. And I’ve named my function my_bzero so it doesn’t conflict with the libc’s bzero. Then, I try my bzero with the following C program:
#include <stdio.h>
#define ZEROED_LEN (10)
void my_bzero(void* addr, long unsigned len);
int main() {
char test[10] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
my_bzero(test, ZEROED_LEN);
printf("%d\n", test[0]);
printf("%d\n", test[1]);
printf("%d\n", test[2]);
printf("%d\n", test[3]);
printf("%d\n", test[4]);
printf("%d\n", test[5]);
printf("%d\n", test[6]);
printf("%d\n", test[7]);
printf("%d\n", test[8]);
printf("%d\n", test[9]);
return 0;
}
Everything works as expected.
“Repeat String Operations”
School 42’s course on assembly suggests learning about “Repeat String Operations”. In the x64 instruction set, I see references to these instructions: REP, REPE, REPZ, REPNE and REPNZ. They are supposed to be useful for functions like strlen, so that’s what I’d like to try and clone from libc.
The x64 instruction set shows that the operands of these instructions are of type m8, m16, etc:

However, in this course about “String instructions” by Ben Howard, there are examples without operands:
MOV DI, DX ;Starting address in DX (assume ES = DS)
MOV AL, 0 ;Byte to search for (NUL)
MOV CX, -1 ;Start count at FFFFh
CLD ;Increment DI after each character
REPNE SCASB ;Scan string for NUL, decrementing CX for each char
So I try using SCAS without operands to reproduce strlen’s behavior in assembly:
section .text
global my_strlen
my_strlen:
mov rsi, rdi ; backup rdi
mov al, 0 ; look for \0
repne scas ; actually do the search
sub rdi, rsi ; save the string length
dec rdi ; don't count the \0 in the string length
mov rax, rdi ; save the return value
ret
But that doesn’t compile:
hello.s:7: error: parser: instruction expected
After multiple searches, and for a reason I don’t remember at the time of writing this, I search for “nasm prefix instruction expected” on Google and luckily find a tip regarding the use of “repeat string operations” with nasm on Stackoverflow:
NASM doesn’t support the ‘LODS’, ‘MOVS’, ‘STOS’, ‘SCAS’, ‘CMPS’, ‘INS’, or ‘OUTS’ instructions, but only supports the forms such as ‘LODSB’, ‘MOVSW’, and ‘SCASD’ which explicitly specify the size of the components of the strings being manipulated.
Given that my goal is to compare each and every byte, one after the other, I guess I can use the “byte version”, that’s SCASB:
section .text
global my_strlen
my_strlen:
mov rsi, rdi ; backup rdi
mov al, 0 ; look for \0
repne scasb ; actually do the search
sub rdi, rsi ; save the string length
dec rdi ; don't count the \0 in the string length
mov rax, rdi ; save the return value
ret
This compiles fine. So I test it with a C program:
#include <stdio.h>
#define ZEROED_LEN (10)
void my_bzero(void* addr, long unsigned len);
long unsigned my_strlen(const char *s);
int main() {
char test[10] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
my_bzero(test, ZEROED_LEN);
printf("%d\n", test[0]);
printf("%d\n", test[1]);
printf("%d\n", test[2]);
printf("%d\n", test[3]);
printf("%d\n", test[4]);
printf("%d\n", test[5]);
printf("%d\n", test[6]);
printf("%d\n", test[7]);
printf("%d\n", test[8]);
printf("%d\n", test[9]);
printf("length: %lu\n", my_strlen("test"));
printf("length: %lu\n", my_strlen(""));
printf("length: %lu\n", my_strlen("hello world"));
return 0;
}
The output looks OK at first sight:
0
0
0
0
0
0
0
0
0
0
length: 4
length: 0
length: 11
However, there is actually a bug. When I remove the bzero code, I have the following test script:
#include <stdio.h>
long unsigned my_strlen(const char *s);
int main() {
printf("length: %lu\n", my_strlen("test"));
printf("length: %lu\n", my_strlen(""));
printf("length: %lu\n", my_strlen("hello world"));
printf("length: %lu\n", my_strlen("bla"));
return 0;
}
And with that, the output is not at all OK:
length: 18446744073709551615
length: 0
length: 11
I think to myself: I know that the char test[10] table was allocated on the stack, maybe this is the “stack alignment” coming back to bite me? But after looking around a bit, I realise that Ben Howard puts -1 in the CX register. When I do this, my code works too:
section .text
global my_strlen
my_strlen:
mov rcx, -1
mov rsi, rdi ; backup rdi
mov al, 0 ; look for \0
repne scasb ; actually do the search
sub rdi, rsi ; save the string length
dec rdi ; don't count the \0 in the string length
mov rax, rdi ; save the return value
ret
This is the output I get with the test program in C:
length: 4
length: 0
length: 11
Copying and pasting code from Ben Howard without understanding it is no fun though. So I look for the reason why mov rcx, -1 magically fixes things. The answer is in the REP instruction algorithm inside the x64 instruction set documentation:
WHILE CountReg ≠ 0
DO
Service pending interrupts (if any);
Execute associated string instruction;
CountReg ← (CountReg – 1);
IF CountReg = 0
THEN exit WHILE loop; FI;
IF (Repeat prefix is REPZ or REPE) and (ZF = 0)
or (Repeat prefix is REPNZ or REPNE) and (ZF = 1)
THEN exit WHILE loop; FI;
OD;
This pseudo-code shows that if CountReg (RCX in my case), reaches 0, then the loop stops. What matters to me though, is the Repeat prefix is REPNE condition. That means that RCX must never reach 0. The simple way to prevent that is setting it to -1 so that when it is decremented at CountReg - 1, it never gets to 0.