Migrating from AWS to Heroku

Recently, I’ve been migrating a website from AWS to Heroku to reduce the maintenance burden of AWS EC2 instances and make the website more reliable.
Planning for failure
Before migrating the servers, I make sure there was an easy way to switch back to the old infrastructure, just in case something went wrong. That turns out to be useful later on.
The domain of the website pointed to an AWS ELB via a CNAME record. Heroku also uses CNAME records. So, to switch back from the new, potentially buggy, infrastructure to the old one, all I have to do was keep the old servers up and make update the CNAME record.
Having a low “Time To Live” (TTL) for the CNAME record was important to enable quick reverts.

Failing to handle the load
Before moving to Heroku, I try using another PaaS, an alternative to Heroku if you will. It seems very simple to use. No configuration whatsoever. At first sight, I’m very enthusiastic about it. And in my initial tests, the website works nicely with it. No lag. No crashes. No timeouts. I think I’m off to a great start.
But then my enthusiasm catches up to me. I flip the DNS switch over to the new infrastructure. Almost instantly, everything starts crashing. Hundreds of timeouts. The website is completely unusable. Stress starts growing. Support requests start coming in to ask what’s going on. At this point, I call the PaaS support team for help. But they are unable to assist me.
So I look for possible bottlenecks. That too, is difficult, because the PaaS provides almost no monitoring tools. That’s when I realise how important monitoring tools are. Not to mention how much more I should have load tested the new infrastructure before putting it on the front-line.
So yes, using this PaaS is a mistake. It doesn’t work for my use-case. So I switch back to the old AWS infrastructure. Instantly, the website started delivering quick responses again.
That’s how I understand some of Heroku’s value proposition for PHP hosting:
- it lets me customize the Nginx & PHP configuration;
- it lets me scale the number of servers up and down on demand;
- it lets me monitor incoming traffic.
But before blindly trusting Heroku’s feature-set like I have done with the first PaaS, I want to make sure that, this time around, the new infrastructure works properly under production conditions.
What to load test
The website I’m migrating has different kinds of work loads: asynchronous tasks run by workers, static content via Wordpress, APIs which themselves call out to multiple APIs, etc. All of these things have to at least be as fast and stable as they are with AWS.
My first pain point is understanding what the bottleneck would be. What should I load test?
My friend Kim is of great help. He gives me tips about log analysis. He walks me through AWS monitoring dashboards amongst others. They provide lots of useful graphs that can help understand the number of concurrent requests I should plan for. Kim also recommends I take a close look at the number of concurrent database connections and transactions in AWS RDS metrics, which would help more accurately define what tests were required.
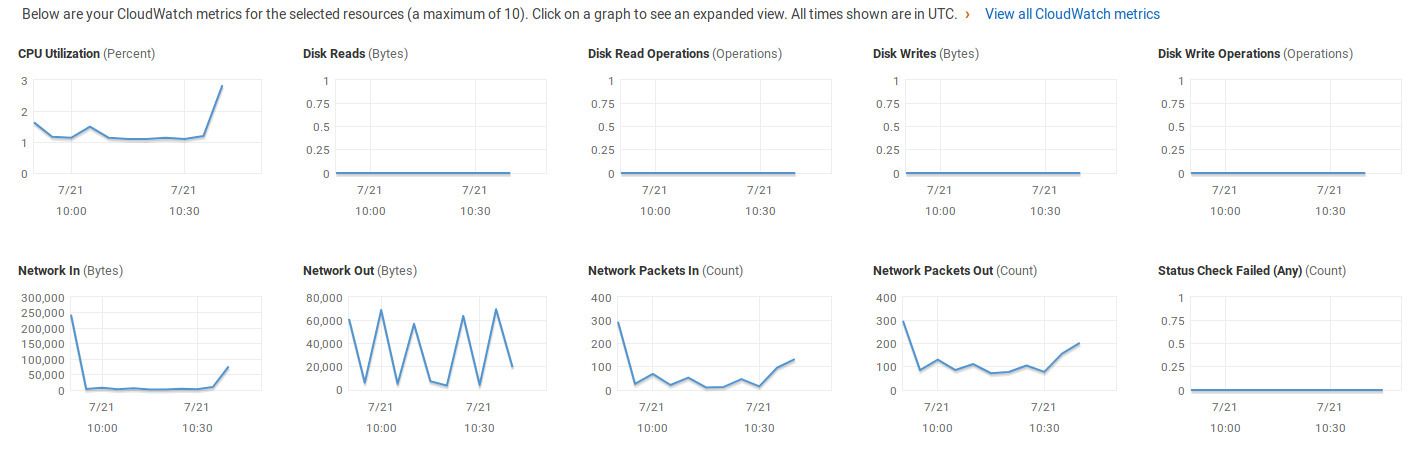
For inspiration, I highly recommend the article about how Github tested a change the way merges were processed. Not everyone needs to go as far as Github, but if Github is as stable as it is despite the high number of users, it is probably because of all the work that goes into testing changes.
How to load test
After I have a somewhat good idea of what to load test, I run tests with more traffic than what would happen in production for the different kinds of workloads that the website runs. If the servers hold up, that’s a good indication that they would also remain available under production traffic.
I hear about the “Apache HTTP benchmarking tool”. What it does, is that it throws a specific number of requests at a specific URL with a predefined concurrency threshold. Here is what it looks like for 1000 requests with a concurrency of 200:
ab -n 1000 -c 200 https://mywebsite.herokudns.com/some-url-to-load-test
The output looks something like this:
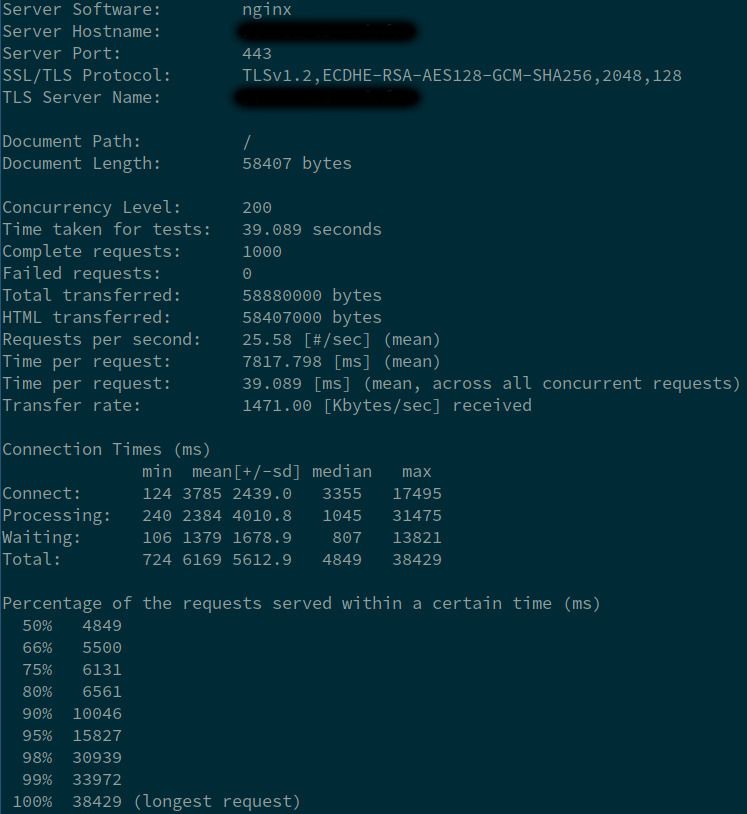
The load tests of all workloads shows good results. Under high load scenario, increasing the number of servers is painless and without interruption of live traffic. Everything looks good. So I go ahead and flip the DNS switch again. We are now in production with the new Heroku based setup.
Edge case detection through monitoring
Heroku has a very helpful “Metrics” view, which displays the number of 4xx and 5xx requests. That’s a good first indicator when it comes to the number of failed requests.
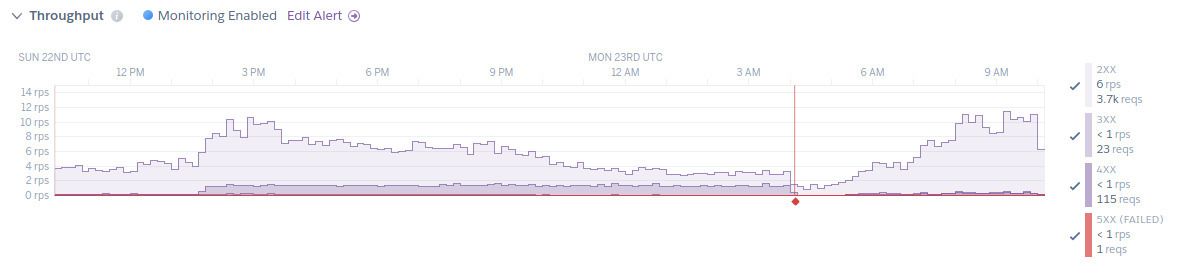
The automated alerts that Heroku sends out can be a bit out of place, but they are generally helpful and help avoid downtime. At the slightest rise in failed requests, a notification is sent out, which can be used to take action: increase the number of servers, look for ways to optimize CPU/memory use, etc.
Looking at Google Analytics performance metrics and Page Speed Insights can also help debunk some bugs.
Some unexpected slowness does appear though:
- Heroku disables GZIP by default, which slows down requests for some static content like Javascript and CSS;
- Heroku has a default memory limit per request of 32MB, which breaks requests that used more than 32MB of RAM;
- Moving from one server on AWS to load balanced Heroku breaks file based caching.
I guess the main takeaway for me is that it takes much longer than expected to iron out all of these bugs.