Errors in PHP web development
2019-01-11
Over the past 3 years, I feel like I’ve seen a lot of interesting errors cases happen as a full-stack web developer, focusing on PHP-driven backends. Pretty much any error that I think would not happen to me ended up happening anyway. Murphy’s law.
Here are some of the error cases I’ve had happen and their effects. I’m writing this down as a reminder for what curious error cases should be handled in a product that needs highly reliable execution.
Timeouts on networked services
Connection timeout
Connection timeouts are somewhat special. They happen in some rare cases, such as when domain name resolution is impossible. That can happen when doing an HTTP request to an API.
In PHP, one of the most used HTTP client is Guzzle. The way Guzzle handles errors can be a bit surprising. Guzzle allows exceptions to be turned off. I use this feature whenever enhanced error handling is required. You’d think that this makes exception handling useless:
$response = $http->request('GET', '/some-uri', [
'connect_timeout' => 5,
'exceptions' => false,
]);
if ($response->getStatusCode() !== 200) {
// handle unexpected status code
// ...
return;
}
Surprisingly, with exceptions turned off in early versions of Guzzle 6, connection timeouts will still raise an exception. More specifically, a ConnectException. This means that exceptions must be handled even when exceptions are disabled, with something like this:
try {
$response = $http->request('GET', '/some-uri', [
'connect_timeout' => 5,
'exceptions' => false,
]);
} catch (ConnectException $e) {
// handle connection timeout
// ...
return;
}
if ($response->getStatusCode() !== 200) {
// handle unexpected status code
// ...
return;
}
This behavior has been made more clear in recent Guzzle versions. The exceptions option is now called http_errors, which makes it more clear that it only prevents exceptions for HTTP requests that get a response (which excludes timeouts).
Next, let’s move on to response timeouts.
Response timeout
The response timeout is a bit different. It happens when the network request
takes to long to get a response. In the case of HTTP, that’s usually because the headers of the response take a long time to come back.
With Guzzle, that’s the timeout option:
$guzzle->request('GET', '/some-uri', [
'timeout' => 5,
]);
Usually, something like 5 seconds should be more than enough. If 5 seconds is not enough, usually that means that things need to be rethought.
Requests that take more than 5 seconds are usually requests that do heavy computation synchronously. Turning the heavy computation into an asynchronous task, handled with a webhook or a polling API is preferable if possible.
Whenever heavy computation needs to be synchronous, 5 seconds might not be enough. In that specific case, using idempotency can make the API immune to timeout errors. This article by Stripe on idempotency is a great read.
Out of memory
Let’s move on to another class of errors which happen all too often and can be quite catastrophic, “Out of memory” (or “OOM”) errors. These errors happen every time a process uses more RAM than it is allowed to use.
In the case of a PHP website, the maximum amount of RAM is specified with the memory_limit INI directive in the php.ini file. Errors similar to OOM might occur if receive files larger than the upload_max_filesize directive or a request body larger than the post_max_size directive.
Here’s a quick example of what these values might look like in php.ini:
memory_limit = 64M
upload_max_filesize = 32M
post_max_size = 32M
OOM errors due to exceeding RAM usage (case of memory_limit being overrun) happen mostly whenever you load to many objects into memory. That can happen if you do something like this on a very large SQL table:
$query = $dbConnection->prepare("SELECT * FROM blog_posts");
$query->execute();
$result = $query->fetchAll(PDO::FETCH_ASSOC);
Here, fetchAll might try to load 1000 blog posts into RAM. This will require more than 64M of RAM and thus cause an “Out of memory” error. This classic case of OOM can be worked around in Symfony, PHP in general and other languages with some techniques I’ve previously described in “Memory management with Symfony commands”.
For OOM errors that come from too large requests (case of upload_max_filesize or post_max_size being overrun), you might want to look into APIs that allow you to delegate file upload to dedicated services. If you’re using S3 for file storage, than AWS S3 pre-signed upload URLs might be the way to go.
Race condition
During development, there is only one user on a website: the developer. Because of that, race conditions rarely occur during development.
In production, things are different. Lots of users are active at once. That means that the slightest possibility for race condition might become a reality.
The most common error I’ve seen is the incorrect use of temporary files.
In PHP, a tempfile is created with tempnam:
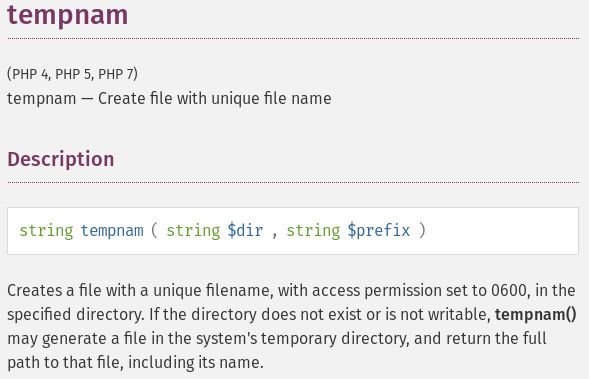
Often times, I’ve seen code that generates PDFs and looks like this:
$tempfile = tempnam(sys_get_temp_dir(), 'user_data_');
if ($tempfile === false) {
// handle error
// ...
return;
}
@rename($tempfile, $tempfile . '.pdf');
$tempfile = $tempfile . '.pdf';
generatePdf($tempfile);
Note how there is no error handling for the call to rename. That will be key in just a moment.
If this script runs on the same server enough times, eventually, two runs will run into a race condition. User A might end up with the PDF of user B, or vice-versa. More specifically, here’s what could happen:
- user A requests a personal data export in PDF form
- server creates
/tmp/user_data_432565for user A - server renames
/tmp/user_data_432565to/tmp/user_data_432565.pdf - user B requests a personal data export in PDF form
- server creates
/tmp/user_data_432565(which is now available, since the file from user A was renamed to something else) for user B renameto/tmp/user_data_432565.pdffails because/tmp/user_data_432565.pdfalready exists from user A’s request, but because there is no error handling, the request of user B continues- server puts data of user A in
/tmp/user_data_432565.pdf - server puts data of user B in
/tmp/user_data_432565.pdf - server sends
/tmp/user_data_432565.pdfto user A and B
And there it is: user A and user B will end up with the data of user B, because it was the last data to be put in the file used by both requests.
Handling all possible errors is of courses a simple solution here. But race conditions can occur in some harder to debug cases as well, such as when you use threads or use the database without proper transaction management.
Let’s have a look at another type of error, full disks.
Full-disk
Yes, disks become full. I’ve had this happen multiple times. Unless you have monitoring systems in place, you probably won’t be notified of the disks being full and data will be dropped silently.
The first time I encountered a full-disk, we were still in early stage, using a single server for everything, including storage of uploaded files. These files filled up the disk and at some point, new files could not be uploaded. Too bad, because our code depended on uploads functioning properly.
The second time, we had installed Docker, a piece of software which had issues with disk usage for a long time, which we didn’t know before seeing our website go down.
The third time, it was because we were storing log files in an s3fs mount. What we missed was that a failure to mount the s3fs would not trigger any error and instead, files would silently fill up the server’s disk until everything blew up.
So basically, what I learn from all of that is that the more immutable a piece of infrastructure is, the easier things are to reason about. If at all possible, mutable data should be stored on bespoke infrastructure with corresponding monitoring services in place.
Null pointer errors
When used without good reason, nullable types are like cancer. They start small and then spread throughout your codebase before they start causing mayhem.
So what’s the problem with nullable types?
The problem with nullable types is not so much null itself. The value null can be handled perfectly well.
Instead, what I’ve seen time and time again is that junior engineers will use nullable types when they don’t want to take the time to understand their software’s requirements. They “just” use a nullable type and that’s it. They don’t worry about what might happen if the value is ever null, because in their initial design, the value is never null.
Then, another engineer comes along and in their new code, the value is null at some point. But the old code doesn’t handle null.
Let’s see an invalid use of a nullable type: take Address type with a field streetNumber that is nullable even though every Address is supposed to have a street number. This kind of thing happens a lot and ends up causing frequent bugs.
And so things start to break down. And the bug tracker starts filling up with errors like these:

So yeah, avoid nullable types if at all possible.
Reasonable uses of nullable types
The only reasonable uses for nullable types are when:
- you have no time to work properly (which can happen if you need a feature shipped very quick);
- or when the
nullvalue expresses is intuitively a valid value.
For instance, here’s a valid usecase for a nullable type: you have BlogPost type persisted in a database and this object has a publishedAt field, which is either a date, if the blog post is published, or null if the object is not yet published.
A trick to get around nullable types
I’ve often seen nullable fields being used as a way to avoid creating a new object. For instance, you have User type that has addressStreetNumber, addressPostcode and addressCity fields that are all nullable, because maybe the user has not yet informed you about their address — in which case all three fields are null.
User
addressStreetNumber: string | null
addressPostcode: string | null
addressCity: string | null
This causes a problem because now, maybe you have users which have only addressStreetNumber that is null but addressPostcode and addressCity not null. What would that mean? Is this user valid?
A architectural trick to get around that is to make the User type have an address field which is of type Address. And make the Address type have 3 non-nullable fields named streetNumber, postcode and city. Now, each user can either have an address, or no address. But each address is valid 100% of the time.
User
address: Address | null
Address
streetNumber: string
postcode: string
city: string
Reducing the amount of places where null is used makes code easier to reason about and reduces the number of bugs in the long run.
SSL certificate of API invalid
More and more, SSL certificate renewals are getting automated, what with Let’s Encrypt and all. But not everything is automated yet. This leaves room for occasional human errors.
I’ve had an SSL certificate be updated in a backwards incompatible manner once. It was a Saturday morning, so as to not disturb customers during the most active hours, which in this case were week hours.
A critical service should try to handle SSL failures securely and gracefully. That means never reverting to insecure connections and trying to revert to a safe alternative whenever possible. As a last resort, dynamically disabling the feature that uses the failing SSL connection whilst having alerts going out to on-call engineers can be a wise temporary solution.
API unavailable
For all of the reasons discussed in this article, web services break. Bugs occur. And servers fail. That’s when an API may become unavailable. It may be unavailable for a few seconds only, or for a prolonged period of time.
When an API is unavailable for a brief moment, there is a simple method we’ve used: retrying. That’s when you run the API call multiple times until it works. Usually, retrying will look something like this:
$retries = 5;
while ($retries !== 0) {
$apiResult = doApiCall();
if ($apiResult) {
break;
}
$retries--;
}
if (!$apiResult) {
// handle error
// ...
return;
}
// handle successful API call
// ...
Retries are not ideal though: the more you retry, the longer the code runs. This mean that if possible, retrying should be avoided. This means, as software engineers, it is a good idea to assume that APIs can become unavailable at any time and that not handling unavailability transparently will make our product unusable.