Kubernetes explained with food
2023-04-25
I’ve been learning about Kubernetes recently, a computer program used by software engineers to create websites. To make it easier to understand what Kubernetes does and how it works, let’s talk about food.
In order for a restaurant to work well during rush hour, the employees have a set of methods and tools they use. Each table has a number assigned to it, the kitchenware is organized in a specific way, a machine keeps the plates warm, another machine makes payments with a debit card quick and easy. These methods and tools are separate from the food itself, of course, but they help deliver the food in the best possible conditions.

A restaurant with its cooking ware, its tables, its organizational methods that help deliver a good service
Kubernetes has a similar role for software engineering teams, it helps deliver software. When a new version of a software is ready, software engineers use Kubernetes to make it available to customers. Kubernetes brings with it a set of guidelines that make it easy to collaborate on large software projects.
Although Kubernetes may be overkill for some smaller projects, it can be very useful when a software is expected to grow in scope and complexity. In fact, you have most likely been on a website recently that uses Kubernetes behind the scenes, it’s a tool used by more and more companies.
The two main components in Kubernetes
Kubernetes is actually not a single program, but the name for multiple computer programs that work together to provide a large number of software development tools.
From a bird's-eye view, there are two main components: the control plane and the worker nodes. The control plane is like a manager and the worker nodes are their team. The control plane knows what work needs to be done and distributes it to worker nodes.
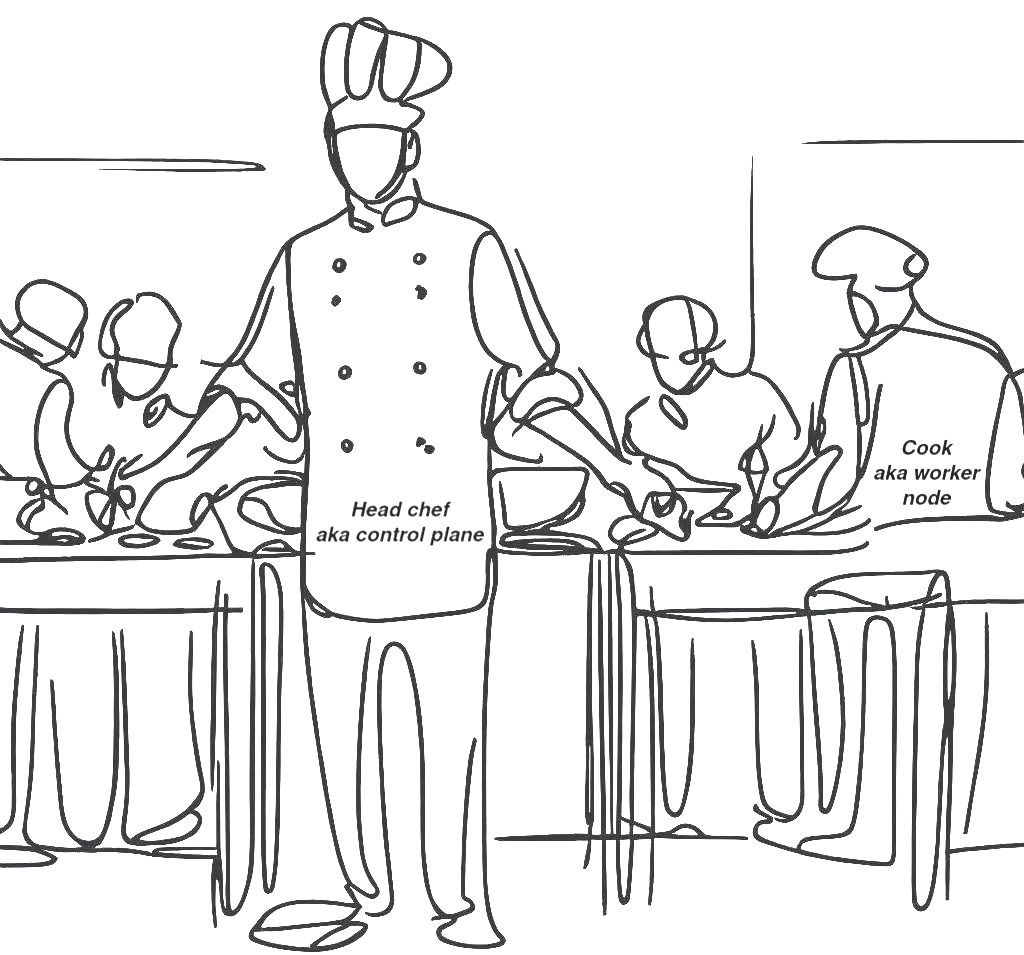
A head chef giving out work to their cooks, similar to how the control plane distributes work to servers called worker nodes
Control plane
If we zoom in to the control plane, we can see that it accomplishes many tasks.
When a request from a software engineer comes in, a control plane component called kube-apiserver steps in and handles it. The kube-apiserver also takes appropriate action when a worker node no longer works.
The control plane decides what part of a website to run on which worker node, depending on how much memory and processing power it needs, through a component called the kube-scheduler.
The control plane also has a concept called controller. Controllers are parts of Kubernetes that guarantee specific conditions are met for what software development teams want to create. For instance, there is a controller that makes sure a website runs on multiple worker nodes in case one fails. There is another controller that makes sure periodic tasks run at a specified time each day.
The control plane is extensible, that is to say we can add things to it to change its behavior. A company with very specific needs can create custom controllers for domain-specific requirements. If that’s a bit blurry, let’s talk about cheesecake.
Cheesecake, can be changed by adding raspberry coulis
A cheesecake can be changed by adding a coulis. In that sense, it is extensible, too.
And just like the raspberry coulis adds to the cheesecake, Kubernetes allows writing bits and pieces of software that change how Kubernetes works and adapt it to a considerable number of customers.
Worker nodes
So we’ve talked about the control plane, but what about the worker nodes?
The worker nodes are simpler: they do what the control plane asks them to do. That could be anything from displaying the website for a local bakery to sending out emails for a marketing campaign.
Declarative vs. imperative
We’ve now seen the two main parts, the control plane and the worker nodes. Let’s see how we can ask Kubernetes to do things.
Kubernetes supports a declarative approach and an imperative approach. Let’s go back to our cheesecake to make things more digestible.
If you want to ask your partner to bake a cheesecake, you can try one of two methods:
- Tell them what you expect and trust them to do the right thing, for instance “I’d like a cheesecake”;
- Or give them step-by-step instructions such as “Buy 150g digestive biscuits, buy plain flour, (…), preheat the oven to 180C, etc”.
Software engineers would say that the first way is declarative and the second is imperative.
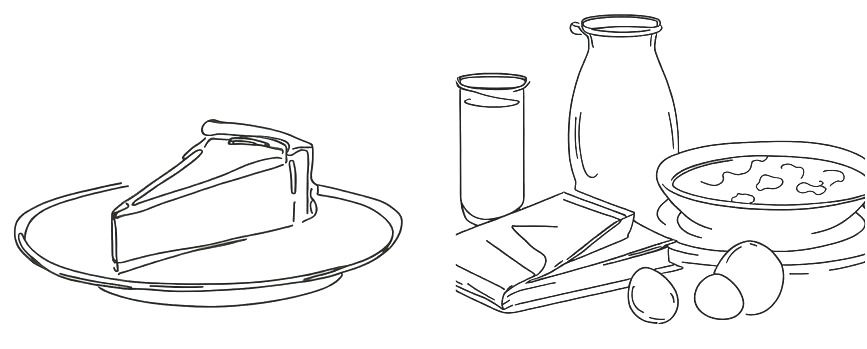
On the left, declarative cheesecake, on the right, imperative cheesecake
With Kubernetes, the declarative way consists in writing a file that describes what you expect, and then trusting Kubernetes to do whatever needs to be done to meet your expectation. To run a website on a single server, you’d need to describe your expectation with a text file that looks like this. Don't bother understanding all of it, it's meant as an example of what a software engineer might be working with during their day.
apiVersion: v1
kind: Pod
metadata:
name: my-website
spec:
containers:
- name: my-website
image: my-website:1.0
---
apiVersion: v1
kind: Service
metadata:
name: my-website
spec:
selector:
app.kubernetes.io/name: my-website
ports:
- protocol: TCP
port: 80
The imperative way of talking to Kubernetes consists in telling it step by step what to do. To run the same website on a single server, you would use a program called kubectl in a terminal. You would need to:
- type
kubectl run my-website --image my-website:1.0; - then type
kubectl expose pod my-website --port=80 --name=my-website.
Usually, software development teams use the declarative approach with Kubernetes because it makes collaboration easier. But the imperative method can be useful from time to time too.
So, there you go. Now, you know what Kubernetes is and how to use it, in a nutshell. It's a computer program used by software engineers to ease the development of other computer programs. It can do many things. And it can be used either by writing text files or using the kubectl software.